


Chinas führendes Technologieunternehmen Tencent hat gerade ein neues Modell für künstliche Intelligenz angekündigt, das in der Lage ist, mit nur einem einzigen Eingabebild Videos zu erstellen, die Bewegungen im dreidimensionalen Raum simulieren.

Das System mit dem Namen HunyuanWorld-Voyager generiert kurze Clips mit Tiefeninformationen, die dann in eine 3D-Punktmatrix rekonstruiert werden können. Dies eröffnet Inhaltserstellern neue Möglichkeiten, ermöglicht jedoch keine vollständige Interaktion mit 3D-Modellen.
HunyuanWorld-Voyager ist ein offen gewichtetes Modell, das Sequenzen von 49 Bildern – etwa zwei Sekunden Video – generiert. Benutzer können jedoch Clips miteinander verknüpfen, um mehrere Minuten ununterbrochenes Filmmaterial zu erstellen.
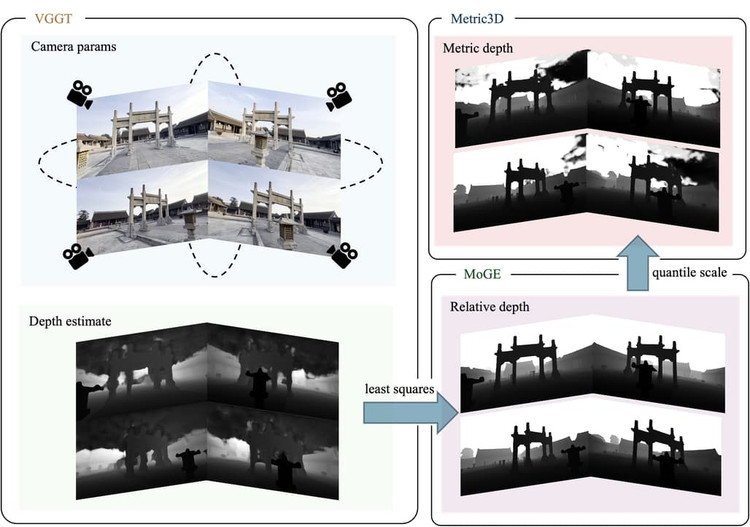
Ars Technica weist darauf hin, dass Objekte ihre relative Position beibehalten, wenn der Betrachter die Perspektive der virtuellen Kamera ändert, und die Umgebung wirkt, als wäre sie vollständig dreidimensional. Obwohl das Endergebnis immer noch ein zweidimensionales Video ist, ermöglichen die zugehörigen Tiefendaten laut Tencent eine 3D-Rekonstruktion ohne traditionelle Modellierungstechniken.

Voyager kombiniert Eingangsbilder mit benutzerdefinierten Kamerapfaden. Der Benutzer gibt Bewegungen wie Schwenken, Neigen oder Bewegen durch die Szene vor, und das System generiert gleichzeitig ein Farbvideo und eine Tiefenkarte. Erscheint ein Objekt im Video, zeichnen die ausgegebenen Tiefendaten dessen relative Entfernung zum korrekten Standort auf.
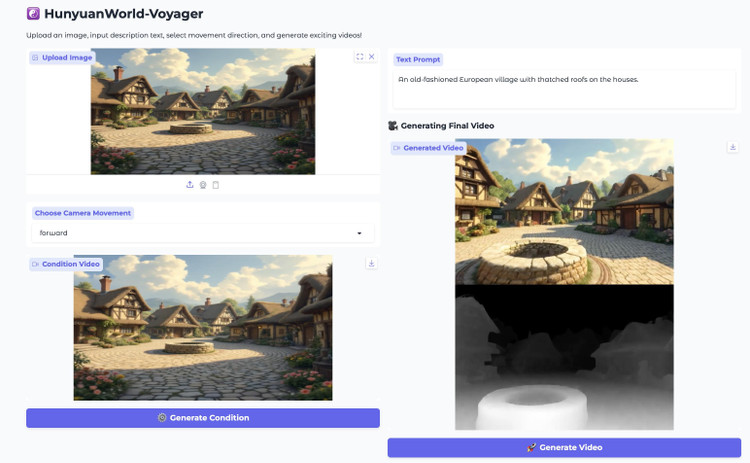
Eine sekundäre Komponente, die im technischen Dokument von Tencent als „World Cache“ bezeichnet wird, speichert 3D-Punktwolken, während das System neue Frames generiert.

Bei jeder Kamerabewegung projiziert Voyager diese Punkte zurück in zwei Dimensionen und verwendet sie als Referenz. Dieser Prozess stellt sicher, dass nachfolgende Frames mit dem zuvor generierten Inhalt übereinstimmen, und trägt so zur Wahrung der räumlichen Konsistenz bei.
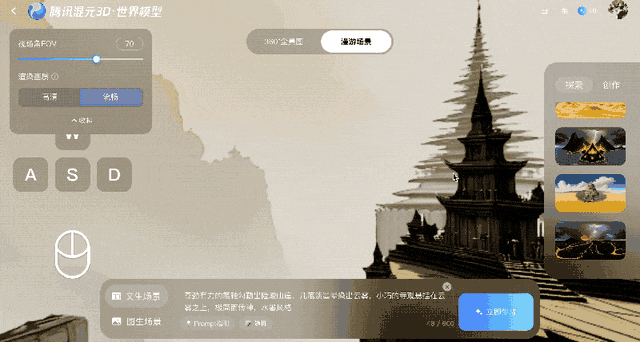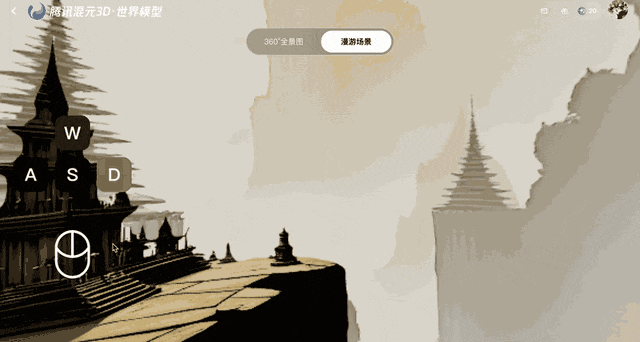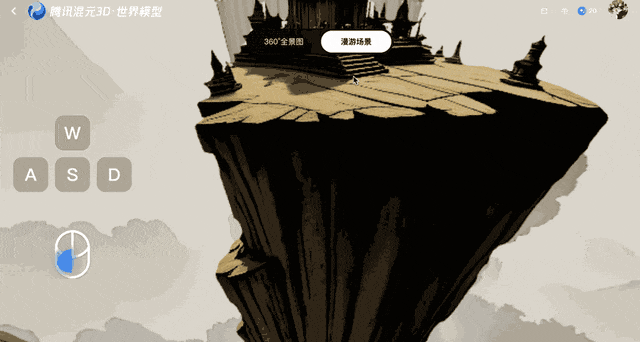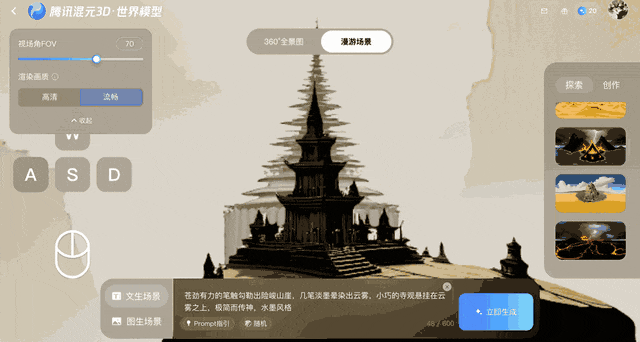
Dieses Modell schützt vor Verzerrungen nach der Erstellung der Einzelbilder, indem es diese in 3D-Punkte umwandelt, die dann zum Vergleich an das System zurückgesendet werden. Diese Rückkopplungsschleife gewährleistet die geometrische Stabilität, auch wenn sich mit der Zeit Fehler ansammeln.
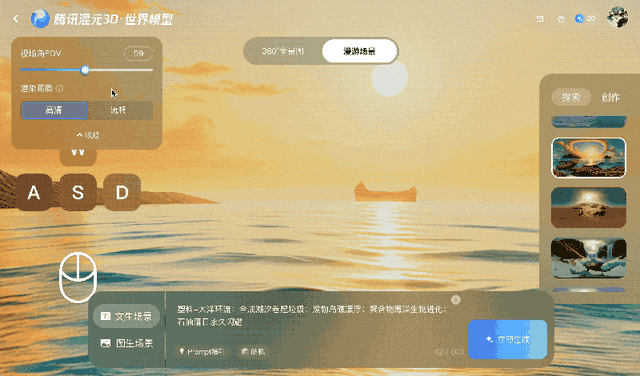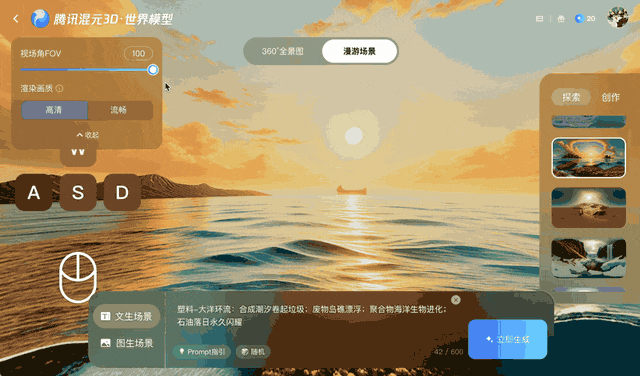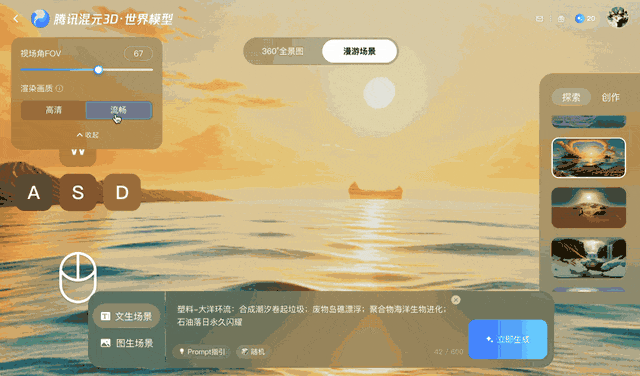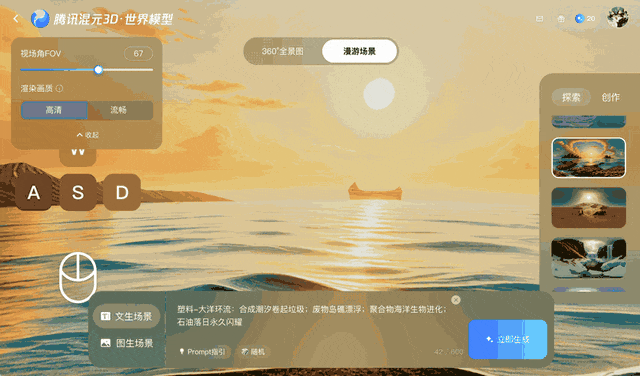
Bei dieser Methode bleibt das Video einige Minuten lang stimmig, bei längeren oder komplexeren Kamerabewegungen, insbesondere bei 360°-Drehungen, hat sie jedoch Probleme.
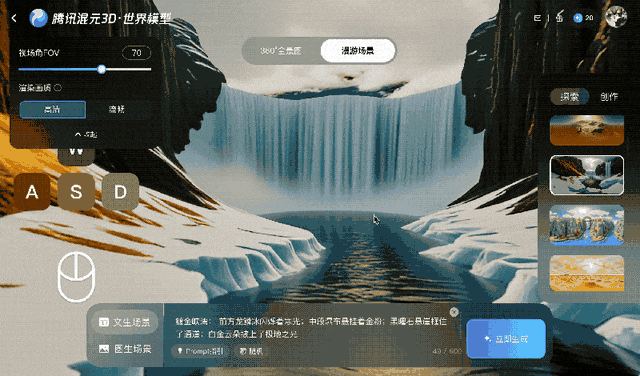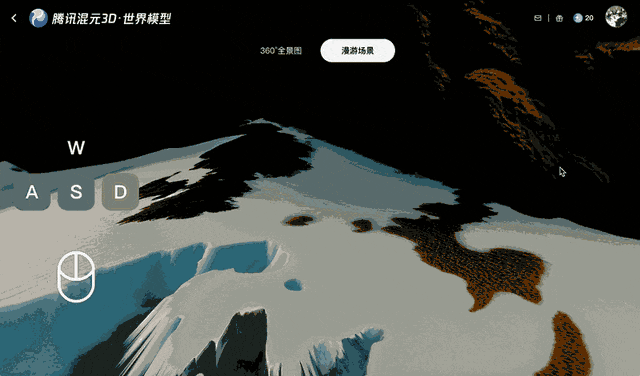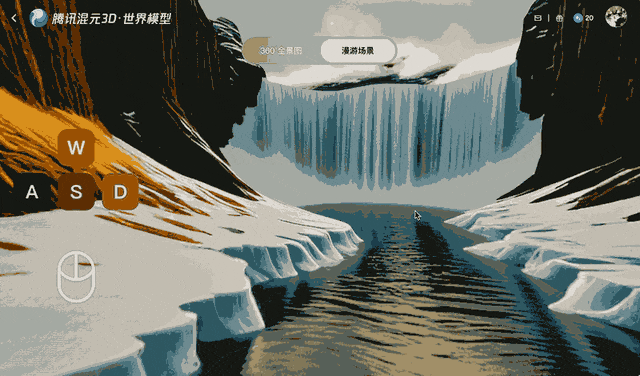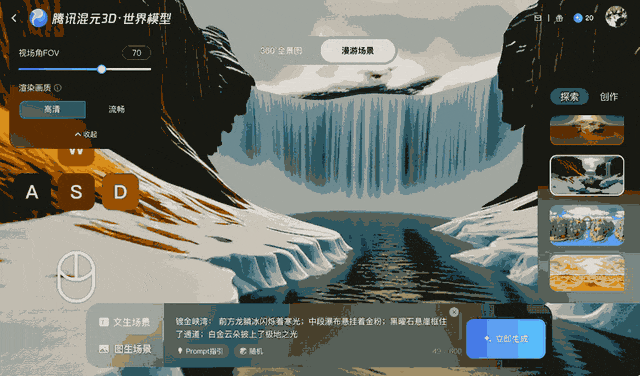
Tencent trainierte Voyager anhand von über 100.000 Videoclips, darunter Realaufnahmen und mit der Unreal Engine erstellte Szenen. Dieser umfangreiche Datensatz vermittelte dem System, wie sich Kameras typischerweise in einer dreidimensionalen Umgebung bewegen. Ein separater automatisierter Prozess generierte Trainingseingaben, indem er die Videoclips scannte, um die Tiefe für jedes Bild zu berechnen. Dadurch entfiel die Notwendigkeit, die Daten manuell zu beschriften.

Das System erfordert enorme Rechenleistung. Für die Ausführung des Modells mit einer Auflösung von 540p sind mindestens 60 GB GPU-Speicher erforderlich, für optimale Ergebnisse werden 80 GB empfohlen. Tencent hat die Modellgewichte auf Hugging Face bekannt gegeben und unterstützt sowohl Single-GPU- als auch Multi-GPU-Setups. Durch die Nutzung der xDiT-Plattform skaliert die Leistung laut Unternehmen horizontal – ein System mit acht GPUs kann Filmmaterial etwa 6,7-mal schneller verarbeiten als ein System mit einer einzelnen GPU.

Die meisten generativen Videomodelle generieren jedes Bild ohne geometrische Konsistenz. Sora von OpenAI beispielsweise priorisiert visuellen Realismus gegenüber 3D-Konsistenz. Voyager verfolgt einen anderen Ansatz und sorgt für eine saubere Geometrie über alle Bilder hinweg durch feedbackbasierte Mustererkennung statt durch vollständiges 3D-Verständnis.

Auf dem WorldScore, einer von Stanford-Forschern entwickelten Skala zur Bewertung 3D-Weltgenerierungssystems, erreichte Voyager 77,62 Punkte. Laut Tencents Bericht war dies die höchste Punktzahl unter vergleichbaren Modellen und übertraf WonderWorld mit 72,69 Punkten und CogVideoX-I2V mit 62,15 Punkten. Voyager übertraf WonderWorld in stilistischer Konsistenz und subjektiver Qualität, blieb jedoch bei der Kameraführung zurück.

Trotz der vielversprechenden Ergebnisse ist das System mit einem wichtigen Vorbehalt verbunden: einigen Lizenzbeschränkungen. Wie bei anderen Modellen der Hunyuan-Suite von Tencent untersagt Tencent die Nutzung von Voyager in der Europäischen Union, Großbritannien und Südkorea. Für kommerzielle Einsätze mit mehr als 100 Millionen aktiven Nutzern pro Monat verlangt das Unternehmen zudem zusätzliche Vereinbarungen.

Die Ausgabequalität stellt einen enormen Fortschritt für KI-generierte Umgebungen dar. Aufgrund des hohen Rechenaufwands und der aktuellen Einschränkungen bei der Szenenkonsistenz kann es jedoch noch einige Zeit dauern, bis Systeme wie Voyager vollständig interaktive Echtzeit-Erlebnisse unterstützen. Derzeit eignet sich das System wahrscheinlich vor allem für die Videoerstellung und experimentelle 3D-Rekonstruktions-Workflows.
Quelle: https://khoahocdoisong.vn/mo-hinh-ai-bien-mot-buc-anh-duy-nhat-thanh-the-gioi-3d-post2149050727.html




![[Foto] Erinnerungen an alte Mittherbstlaternen wieder aufleben lassen](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/9/8/d17f9089e4d6492eb7745c74f271a250)




















![[Foto] Beeindruckende Ausstellungsstände von Provinzen und Städten auf der Ausstellung „80 Jahre Reise der Unabhängigkeit – Freiheit – Glück“](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/9/7/cd63e24d8ef7414dbf2194ab1af337ed)






























































Kommentar (0)