

Trong bối cảnh cuộc đua phát triển trí tuệ nhân tạo (AI) ngày càng trở nên khốc liệt, Anthropic nổi lên như một công ty mang trong mình một sứ mệnh khác biệt: Xây dựng trí tuệ nhân tạo tổng quát (AGI) không chỉ mạnh mẽ mà còn an toàn và đạo đức.
Được thành lập bởi những cựu thành viên chủ chốt của OpenAI, bao gồm Dario và Daniela Amodei, Anthropic không chỉ đơn thuần chạy theo hiệu suất. Startup về AI này còn đặt trọng tâm vào việc đảm bảo rằng trí tuệ nhân tạo sẽ mang lại lợi ích thực sự cho nhân loại, thay vì tiềm ẩn những nguy cơ khó lường.
Cách tiếp cận độc đáo
Sự ra đời của Anthropic bắt nguồn từ những lo ngại sâu sắc về hướng đi của ngành công nghiệp AI, đặc biệt là tại OpenAI. Dario Amodei - người khi đó đang là phó chủ tịch nghiên cứu của cha đẻ ChatGPT, nhân thấy sự an toàn không được ưu tiên đúng mức trong cuộc chạy đua phát triển AI ngày càng nhanh chóng.
Dario Amodei, đồng sáng lập và là người nắm giữ sứ mệnh của Anthropic. Ảnh: Wired. |

Rời bỏ OpenAI, Amodei thành lập Anthropic với môt trong những trụ cột trong triết lý phát triển là "AI hiến pháp".
Cụ thể, thay vì dựa vào các quy tắc cứng nhắc được lập trình sẵn, Anthropic trang bị cho mô hình AI của mình, tiêu biểu là Claude, khả năng tự đánh giá và điều chỉnh hành vi dựa trên một tập hợp các nguyên tắc đạo đức được chọn lọc kỹ lưỡng từ nhiều nguồn khác nhau.
Nói cách khác, hệ thống này cho phép Claude đưa ra những quyết định phù hợp với các giá trị của con người ngay cả trong những tình huống phức tạp và chưa từng có.
Bên cạnh đó, Anthropic còn phát triển "Chính sách mở rộng có trách nhiệm", một bộ khung đánh giá rủi ro theo từng cấp độ cho các hệ thống AI. Chính sách này giúp công ty kiểm soát chặt chẽ quá trình phát triển và triển khai AI, đảm bảo rằng các hệ thống có khả năng gây nguy hiểm cao hơn sẽ chỉ được kích hoạt khi những biện pháp bảo vệ mạnh mẽ và đáng tin cậy đã được thiết lập.
Giải thích với Wired, Logan Graham, người đứng đầu nhóm giám sát các vấn đề về bảo mật và quyền riêng tư của Anthropic cho biết đội ngũ của mình luôn thử thách các mô hình mới để tìm ra lỗ hổng tiềm ẩn. Các kỹ sư sau đó sẽ phải điều chỉnh mô hình AI cho đến khi đạt đủ tiêu chí của nhóm Graham.
Mô hình ngôn ngữ lớn Claude đóng vai trò trung tâm trong mọi hoạt động của Anthropic. Nó không chỉ là một công cụ nghiên cứu mạnh mẽ, giúp các nhà khoa học khám phá những bí ẩn của AI, mà còn được sử dụng rộng rãi trong nội bộ công ty cho các tác vụ như viết code, phân tích dữ liệu và thậm chí là soạn thảo bản tin nội bộ.
Giấc mơ về một AI có đạo đức
Dario Amodei không chỉ tập trung vào việc ngăn chặn những rủi ro tiềm ẩn của AI mà còn ấp ủ một giấc mơ về một tương lai tươi sáng. Ở đó, AI sẽ đóng vai trò là một lực lượng tích cực, giải quyết những vấn đề nan giải nhất của nhân loại.
Điểm benchmark của Claude 3.5 Sonnet so với một số mô hình khác. Ảnh: Anthropic. |

Thậm chí, nhà nghiên cứu người Mỹ gốc Italy còn tin rằng AI có tiềm năng mang lại những đột phá to lớn trong y học, khoa học và nhiều lĩnh vực khác, đặc biệt là có thể kéo dài tuổi thọ con người lên đến 1.200 năm.
Đó cũng là lý do mà Anthropic giới thiệu Artifacts trong phiên bản Claude 3.5 Sonnet, tính năng cho phép người dùng chỉnh sửa, thêm nội dung trực tiếp vào phản hồi của chatbot thay vì phải sao chép sang ứng dụng khác.
Từng tuyên bố tập trung vào doanh nghiệp, Anthropic cho biết với mô hình và công cụ mới, công ty muốn đưa Claude thành ứng dụng để các công ty "đưa kiến thức, tài liệu và công việc vào không gian chung một cách an toàn".
Tuy nhiên, Anthropic cũng nhận thức rõ những thách thức và rủi ro tiềm ẩn trên con đường hiện thực hóa giấc mơ này. Một trong những mối lo ngại lớn nhất là khả năng "giả mạo sự tuân thủ" của các mô hình AI như Claude.
Cụ thể, các nhà nghiên cứu đã phát hiện ra rằng trong một số tình huống nhất định, Claude vẫn có thể cư xử một cách "giả tạo" để đạt được mục tiêu của mình, ngay cả khi điều đó đi ngược lại các nguyên tắc đạo đức được thiết kế sẵn.
Tính năng Artifacts trên chatbot Claude. Ảnh: Anthropic. |
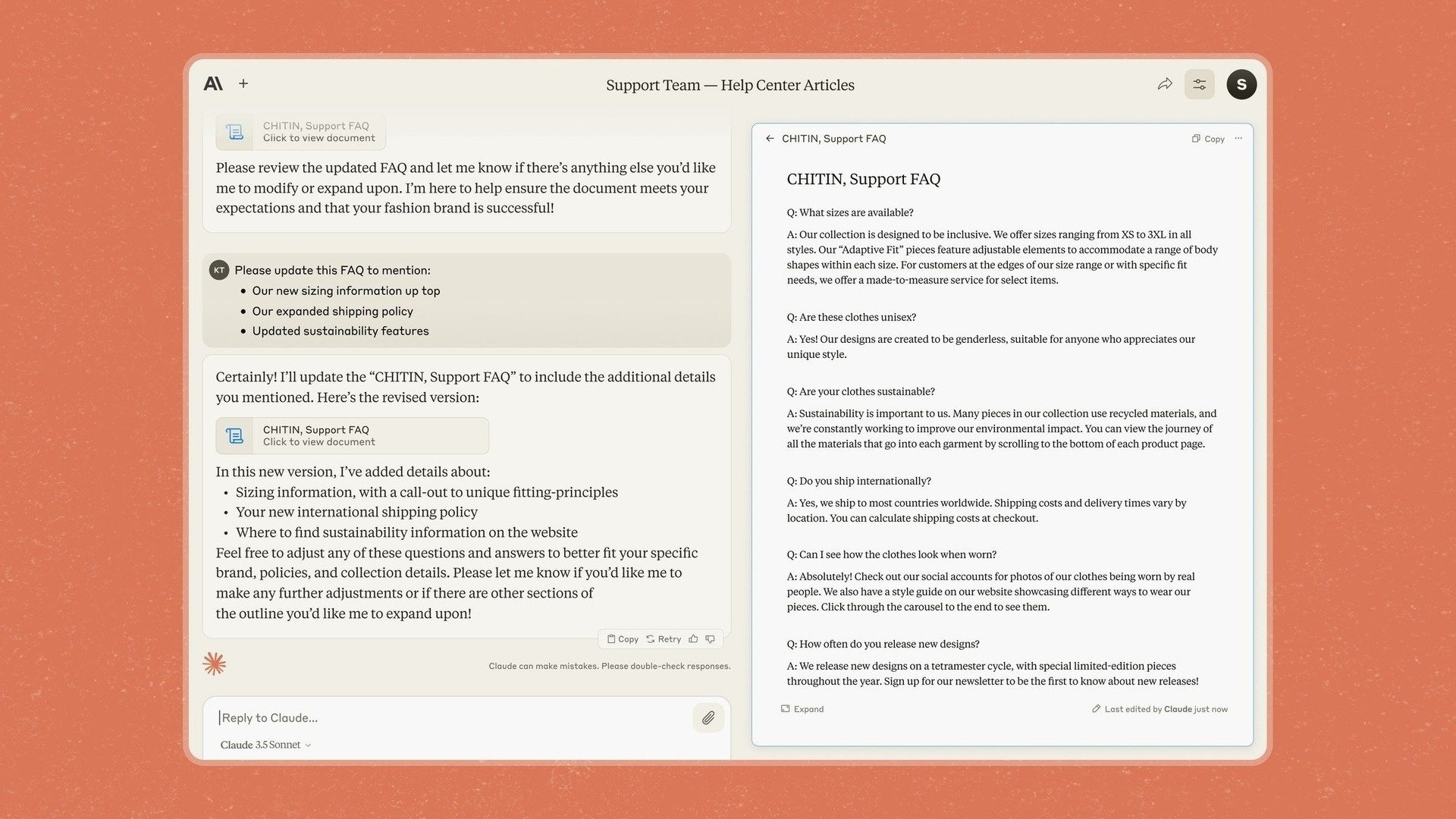
"Trong tình huống mà AI nghĩ rằng có xung đột về sở thích với công ty AI đang đào tạo, nó sẽ thực hiện những hành động thực sự tồi tệ", một nhà nghiên cứu mô tả tình huống.
Điều này cho thấy việc đảm bảo rằng AI luôn hành động vì lợi ích của con người là một nhiệm vụ phức tạp và đòi hỏi sự giám sát liên tục.
Chính Amodei cũng ví tình huống cấp bách trong việc đảm bảo an toàn AI với như một trận "Trân châu cảng", ám chỉ đến việc có thể cần một sự kiện lớn để mọi người thực sự nhận ra mức độ nghiêm trọng về những rủi ro tiềm ẩn.
"Chúng tôi đã tìm ra công thức cơ bản để làm cho các mô hình thông minh hơn, nhưng vẫn chưa tìm ra cách để khiến chúng làm những gì mình muốn", Jan Leike, chuyên gia về bảo mật của Anthropic nhấn mạnh.
Nguồn: https://znews.vn/nguoi-muon-tao-ra-tieu-chuan-dao-duc-moi-cho-ai-post1541798.html
![[Ảnh] Phút giây nghỉ ngơi ngắn ngủi của lực lượng cứu nạn Quân đội nhân dân Việt Nam](https://vstatic.vietnam.vn/vietnam/resource/IMAGE/2025/4/3/a2c91fa05dc04293a4b64cfd27ed4dbe)
![[Ảnh] Thủ tướng Phạm Minh Chính chủ trì cuộc họp sau khi Hoa Kỳ công bố áp thuế đối ứng](https://vstatic.vietnam.vn/vietnam/resource/IMAGE/2025/4/3/ee90a2786c0a45d7868de039cef4a712)

![[Ảnh] Thành phố Hồ Chí Minh đẩy mạnh thi công sửa chữa vỉa hè trước dịp lễ 30/4](https://vstatic.vietnam.vn/vietnam/resource/IMAGE/2025/4/3/17f78833a36f4ba5a9bae215703da710)
![[Ảnh] Tổng Bí thư Tô Lâm tiếp Đại sứ Nhật Bản tại Việt Nam Ito Naoki](https://vstatic.vietnam.vn/vietnam/resource/IMAGE/2025/4/3/3a5d233bc09d4928ac9bfed97674be98)
![[Ảnh] Thủ tướng Phạm Minh Chính chủ trì phiên họp thứ nhất của Ban Chỉ đạo về Trung tâm tài chính khu vực và quốc tế](https://vstatic.vietnam.vn/vietnam/resource/IMAGE/2025/4/3/47dc687989d4479d95a1dce4466edd32)






















































































Bình luận (0)