
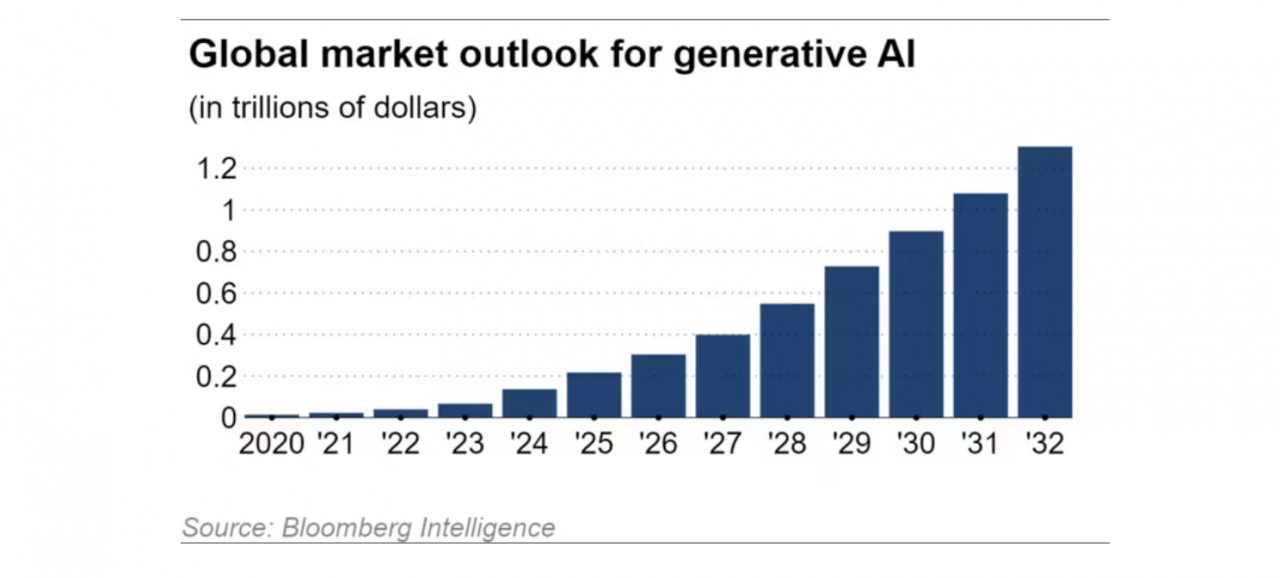
Der globale Markt für synthetische KI wächst nach Schätzungen von Bloomberg Intelligence jährlich um 42 % und dürfte bis 2032 1,3 Billionen US-Dollar erreichen, also etwa das 32-fache seines Volumens von 40 Milliarden US-Dollar im Jahr 2022.
Vorreiter sind US-amerikanische Technologieunternehmen wie OpenAI, Google und Amazon – Technologiegiganten mit viel Geld und viel Personal.
Trotz der starken Konkurrenz habe sich VinGroup für die Entwicklung einer eigenen Version entschieden und dabei vietnamesische Daten verwendet, um eine KI mit höherer Genauigkeit als die ausländischer Konkurrenz zu schaffen, sagte Vu Ha Van, Mathematikprofessor an der Yale University und wissenschaftlicher Leiter von VBD.
Bisher wurden generative KI-Programme hauptsächlich mit englischen Daten trainiert. Das bedeutet, dass es relativ wenige Daten aus Vietnam gibt, was die Genauigkeit dieser Programme in Bezug auf die lokale Kultur, Geschichte und Gesetze verringert.
Das große Sprachmodell (LLM) von ViGPT soll aus 1,6 Milliarden Parametern bestehen, einige Prozent der Größe von GPT-4 von OpenAI.
Mehr Parameter bedeuten normalerweise eine höhere Intelligenz. Laut einer allgemeinen KI-Bewertung, die speziell auf den vietnamesischen Markt zugeschnitten ist, übertraf ViGPT jedoch viele ausländische Konkurrenten und erreichte den zweithöchsten Wert nach ChatGPT.
Die VinFast Group wird KI-Technologie bei der Produktion von Elektrofahrzeugen einsetzen. Fahrer können das Fahrzeug über vietnamesische Sprachbefehle steuern. Die Gruppe plant außerdem, KI in den Bereichen Finanzen, Versicherungen und Logistik einzusetzen.
Der Wettlauf um die Entwicklung von KI in Asien
Schätzungsweise sprechen nur etwa 5 % der Weltbevölkerung Englisch als Muttersprache. Das bedeutet, dass ein enormer potenzieller Bedarf an KI für Nicht-Muttersprachler besteht.
In Japan entwickeln Unternehmen KI, die Japanisch generiert. Im August startete der Elektronikriese NEC einen Dienst, der das LLM cotomi nutzt. Der Telekommunikationskonzern NTT wird im März einen Dienst auf Basis von tsuzumi, einem weiteren LLM, einführen. Auch der japanische Mobilfunkanbieter SoftBank entwickelt ein eigenes LLM.
„Das Verständnis japanischer Geschäftspraktiken bietet Vorteile bei der Benutzerfreundlichkeit, beispielsweise beim Beantworten von E-Mails und beim Ausführen von Callcenter-Arbeiten auf natürlichere Weise“, sagte Junichi Miyakawa, Präsident von SoftBank.
Der Wettlauf um die Entwicklung eigener KI wird durch die Risiken einer übermäßigen Abhängigkeit von den USA befeuert, insbesondere im Hinblick auf die internationale Wettbewerbsfähigkeit und die nationale Sicherheit. Zudem gibt es Bedenken, dass der Einsatz von KI-Programmen, die in anderen Ländern entwickelt wurden, zu Datenlecks und der Gefährdung sensibler Informationen führen könnte.
Professor Van sagte, dass der aufstrebende Technologiesektor nicht in den Händen ausländischer Unternehmen bleiben sollte, da immer mehr Studenten KI zum Lernen nutzen, was bedeutet, dass Innovationen einen enormen Einfluss auf die jüngere Generation haben.
In China, das im Technologiebereich mit den USA konkurriert, entwickeln Baidu, Tencent Holdings und Alibaba Group Holding innovative KI. Baidus Ernie Bot hatte Ende letzten Jahres mehr als 100 Millionen Nutzer.
„Das generative Großsprachenmodell, das wir derzeit entwickeln, wird besser für die chinesische Sprache und den chinesischen Markt geeignet sein“, sagte Robin Li, Vorstandsvorsitzender und CEO von Baidu.
Im vergangenen August stellte der südkoreanische Internetdienstanbieter Naver HyperClova X vor, eine synthetische KI, die speziell auf die koreanische Sprache zugeschnitten ist. Das Programm wird in die Suchmaschine und die Online-Shopping-Plattform des Unternehmens integriert, um Nutzern zu helfen, die gewünschten Ergebnisse effizienter zu finden.
Laut Naver ist die koreanische Datenbank 6.500 Mal größer als die koreanische Datenbank von ChatGPT, was zu einer natürlicheren Lesbarkeit des Textes und einer reibungsloseren Spracherkennung führt.
Singapur kündigte im vergangenen Monat Pläne zur Entwicklung von LLMs an, die auf die indonesische, malaysische und thailändische Sprache zugeschnitten sind. Solche Initiativen stehen jedoch vor Herausforderungen, wie beispielsweise dem Mangel an Daten, die zum Trainieren seltener Sprachen verwendet werden können, und der mangelnden Rentabilität der Entwicklung solcher Modelle.

[Anzeige_2]
Quelle



![[Foto] Premierminister Pham Minh Chinh leitet eine Sitzung des Ständigen Regierungsausschusses, um Hindernisse für Projekte zu beseitigen.](https://vphoto.vietnam.vn/thumb/1200x675/vietnam/resource/IMAGE/2025/10/06/1759768638313_dsc-9023-jpg.webp)

































































































Kommentar (0)