

GPU ist das Gehirn des KI-Computers
Einfach ausgedrückt fungiert die Grafikverarbeitungseinheit (GPU) als Gehirn des KI-Computers.
Wie Sie vielleicht wissen, ist die Zentraleinheit (CPU) das Gehirn des Computers. Der Vorteil einer GPU besteht darin, dass sie eine spezialisierte CPU ist, die komplexe Berechnungen durchführen kann. Am schnellsten gelingt dies, indem mehrere GPUs dasselbe Problem lösen. Das Training eines KI-Modells kann jedoch Wochen oder sogar Monate dauern. Nach der Erstellung wird es in ein Front-End-Computersystem integriert, und Benutzer können dem KI-Modell Fragen stellen – ein Prozess, der als Inferenz bezeichnet wird.
Ein KI-Computer mit mehreren GPUs
Die beste Architektur für KI-Probleme ist die Verwendung eines GPU-Clusters in einem Rack, verbunden mit einem Switch auf dem Rack. Mehrere GPU-Racks können in einer Netzwerkhierarchie verbunden werden. Mit zunehmender Komplexität des Problems steigen die GPU-Anforderungen, und manche Projekte erfordern möglicherweise Cluster mit Tausenden von GPUs.
Jeder KI-Cluster ist ein kleines Netzwerk
Beim Aufbau eines KI-Clusters ist es notwendig, ein kleines Computernetzwerk einzurichten, um eine Verbindung herzustellen und es den GPUs zu ermöglichen, zusammenzuarbeiten und Daten effizient auszutauschen.
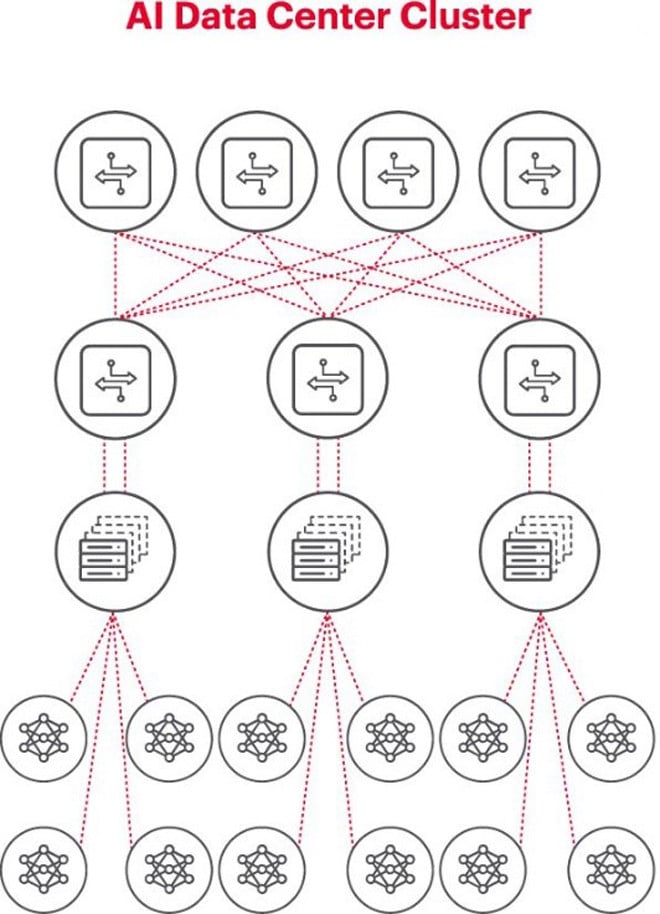
Die obige Abbildung zeigt einen KI-Cluster, wobei die Kreise unten die auf GPUs laufenden Workflows darstellen. Die GPUs sind mit den Top-of-Rack-Switches (ToR) verbunden. Die ToR-Switches sind außerdem mit den über dem Diagramm dargestellten Netzwerk-Backbone-Switches verbunden und veranschaulichen die klare Netzwerkhierarchie, die bei der Beteiligung mehrerer GPUs erforderlich ist.
Netzwerke sind ein Engpass bei der KI-Bereitstellung
Beim Global Summit des Open Computer Project (OCP), bei dem die Delegierten im vergangenen Herbst an der Entwicklung der KI-Infrastruktur der nächsten Generation arbeiteten, brachte der Delegierte Loi Nguyen von Marvell Technology einen wichtigen Punkt zum Ausdruck: „Die Vernetzung ist der neue Engpass.“
Technisch gesehen können hohe Paketlatenzen oder Paketverluste aufgrund von Netzwerküberlastung dazu führen, dass Pakete erneut gesendet werden, was die Auftragsabschlusszeit (JCT) erheblich verlängert. Infolgedessen verschwenden Unternehmen aufgrund ineffizienter KI-Systeme GPUs im Wert von Millionen oder Zehnmillionen Dollar, was sowohl Umsatz als auch Markteinführungszeit kostet.
Messung ist eine Schlüsselvoraussetzung für den erfolgreichen Betrieb von KI-Netzwerken
Um einen KI-Cluster effektiv zu betreiben, müssen GPUs voll ausgelastet sein, um die Trainingszeit zu verkürzen und das Lernmodell optimal einzusetzen, um den Return on Investment zu maximieren. Daher ist es notwendig, die Leistung des KI-Clusters zu testen und zu bewerten (Abbildung 2). Diese Aufgabe ist jedoch nicht einfach, da es in der Systemarchitektur viele Einstellungen und Beziehungen zwischen GPUs und Netzwerkstrukturen gibt, die sich zur Lösung des Problems ergänzen müssen.
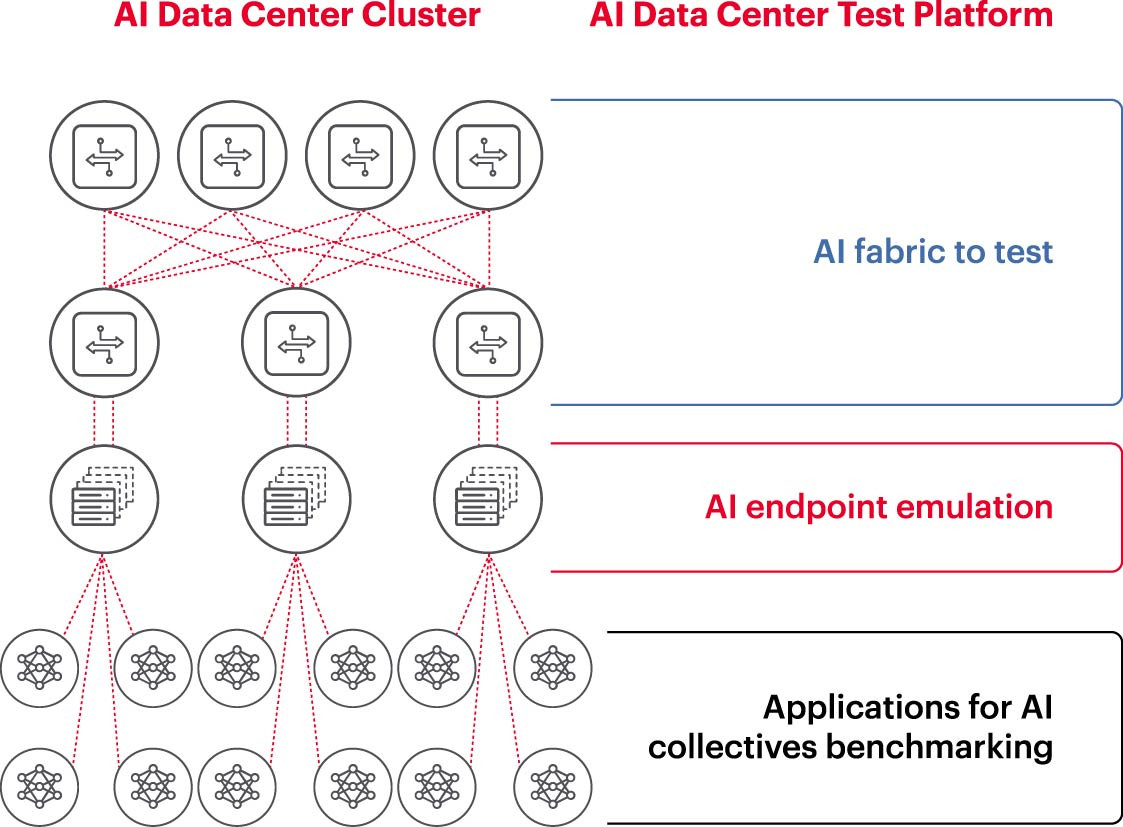
Dies führt zu zahlreichen Herausforderungen bei der Messung von KI-Netzwerken:
- Schwierigkeiten bei der Reproduktion ganzer Produktionsnetzwerke im Labor aufgrund von Einschränkungen hinsichtlich Kosten, Ausrüstung, Mangel an qualifizierten Netzwerk-KI-Ingenieuren, Platz, Strom und Temperatur.
- Durch die Messung am Produktionssystem wird die verfügbare Verarbeitungskapazität des Produktionssystems selbst reduziert.
- Schwierigkeiten bei der genauen Reproduktion der Probleme aufgrund von Unterschieden in Umfang und Reichweite der Probleme.
- Die Komplexität der gemeinsamen Verbindung von GPUs.
Um diese Herausforderungen zu meistern, können Unternehmen eine Auswahl der empfohlenen Setups in einer Laborumgebung testen, um wichtige Kennzahlen wie die Job Completion Time (JCT) und die vom KI-Team erreichbare Bandbreite zu vergleichen und diese mit der Switching-Plattform- und Cache-Auslastung zu vergleichen. Dieses Benchmarking hilft, die richtige Balance zwischen GPU-/Verarbeitungslast und Netzwerkdesign/-setup zu finden. Sobald die Computerarchitekten und Netzwerkingenieure mit den Ergebnissen zufrieden sind, können sie diese Setups in die Produktion überführen und neue Ergebnisse messen.
Unternehmensforschungslabore, akademische Einrichtungen und Universitäten analysieren jeden Aspekt des Aufbaus und Betriebs effektiver KI-Netzwerke, um die Herausforderungen der Arbeit in großen Netzwerken zu bewältigen, insbesondere angesichts der ständigen Weiterentwicklung bewährter Verfahren. Dieser kollaborative, wiederholbare Ansatz ist für Unternehmen die einzige Möglichkeit, wiederholbare Messungen durchzuführen und „Was-wäre-wenn“-Szenarien schnell zu testen, die die Grundlage für die Optimierung von Netzwerken für KI bilden.
(Quelle: Keysight Technologies)
[Anzeige_2]
Quelle: https://vietnamnet.vn/ket-noi-mang-ai-5-dieu-can-biet-2321288.html
































































































Kommentar (0)